5月20日,千问正式发布Qwen3.7-Max——面向智能体时代的新一代旗舰模型,即将通过API提供服务。Qwen3.7-Max致力于成为全能的智能体基座——无论是编写和调试代码、自动化办公流程,还是在跨越数百乃至数千步的长周期(883436)任务中持续自主执行,都能胜任。
据悉,Qwen3.7-Max的核心优势在于智能体能力的广度与深度:编程方面,从前端原型开发到复杂的多文件工程均能驾驭;办公与生产力方面,通过MCP集成和多智能体协作实现工作流自动化;长周期(883436)自主执行方面,在一项长达35小时、超过1000次工具调用的全自主内核优化实验中保持了连贯推理,充分验证了其持久稳定的执行能力;此外,无论部署在Claude Code、OpenClaw、Qwen Code还是其他框架下,都能稳定发挥出色的跨框架泛化能力。
Qwen3.7-Max—即将通过阿里云百炼提供服务:
前沿编程智能体:从前端原型到复杂软件工程
办公生产力与工作流自动化,支持MCP集成和多智能体协作
持续稳定的长周期自主执行能力
跨多种智能体框架的泛化能力您可以通过阿里云百炼API调用(即将上线)。
模型表现
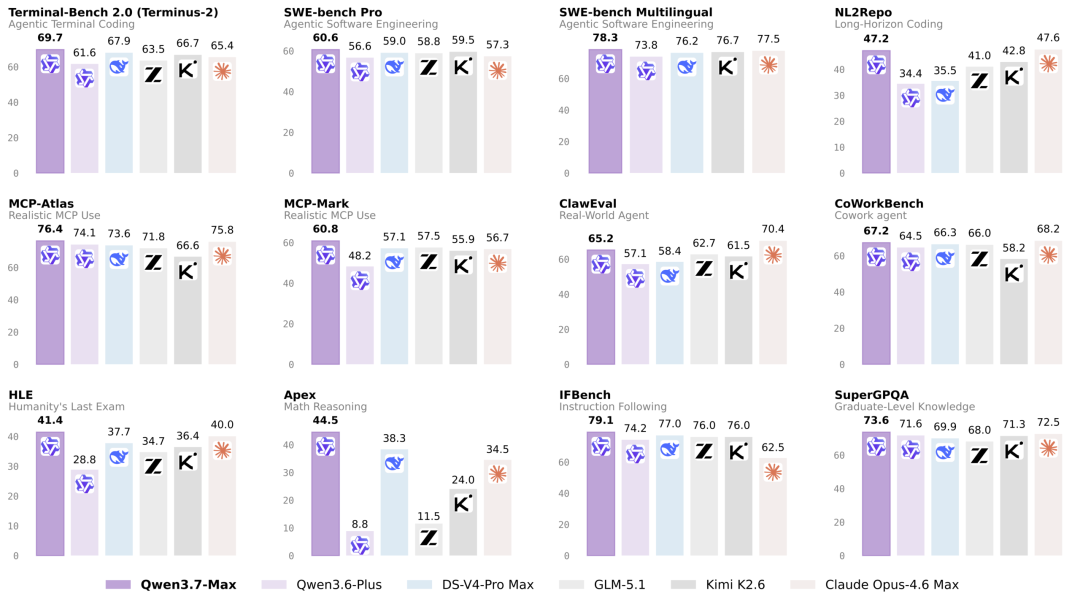
在编程智能体方面,Qwen3.7-Max在SWE-Pro(60.6)、SWE-Multilingual(78.3)、SciCode(53.5)和QwenSVG(1608)上均取得领先表现。在Terminal Bench2.0-Terminus(69.7)上超越DS-V4-Pro Max(67.9)。在SWE-Verified(80.4)上与Opus-4.6Max(80.8)和DS-V4-Pro Max(80.6)表现相当。
在通用智能体方面,提升更为显著。Qwen3.7-Max在MCP-Mark(60.8vs.GLM-5.1的57.5)、MCP-Atlas(76.4vs.Opus-4.6的75.8)和Skillbench(59.2vs.K2.6的56.2)上表现突出,并在Kernel Bench L3(1.98倍中位数加速,96%加速率)上展示了强大的GPU内核优化能力。在BFCL-V4(75.0)、Qwenclaw(64.3)和ClawEval(65.2)上同样表现出色,紧追Opus-4.6Max。在办公自动化基准SpreadSheetBench-v1上得分87.0,处于顶尖水平。
在推理方面,Qwen3.7-Max在GPQA Diamond(92.4vs.Opus-4.6的91.3)、HLE(41.4vs.Opus-4.6的40.0)、HMMT2026Feb(97.1vs.Opus-4.6的96.2)、IMOAnswerBench(90.0vs.DS-V4-Pro的89.8)和Apex(44.5vs.DS-V4-Pro的38.3)上均取得领先成绩,在高难度推理基准上展现了强大实力。
在通用能力与多语言方面,Qwen3.7-Max在IFBench(79.1vs.DS-V4-Pro的77.0)上表现突出,展示了精准的指令遵循能力。在WMT24++(85.8)和MAXIFE(89.2)上同样领先,表明其多语言理解和翻译质量处于一流水平。在SuperGPQA(73.6)和QwenWorldBench(57.3)上同样表现出色。
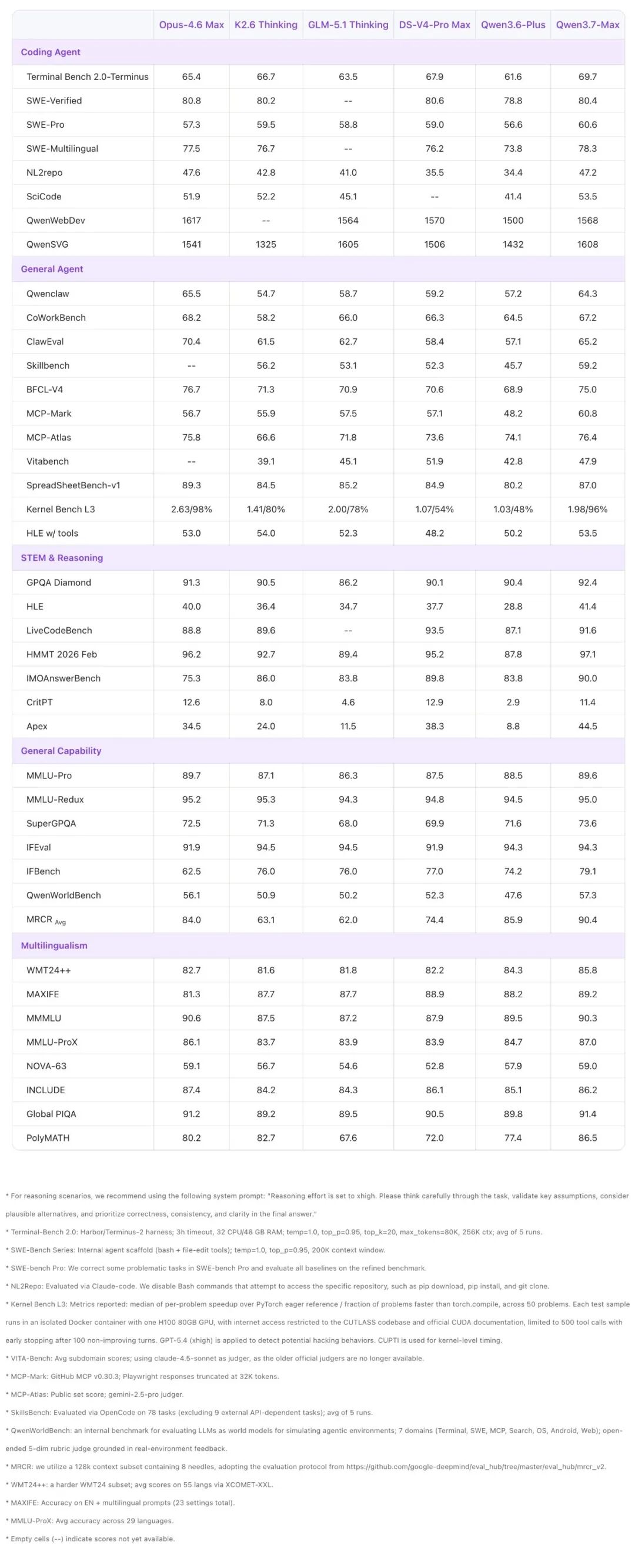
值得强调的是,上述评测分数来自多种不同的智能体框架。Qwen3.7-Max并非针对某一特定框架优化,而是在Claude Code、OpenClaw、Qwen Code和各类自定义工具使用框架下都能稳定发挥,是各类智能体系统的可靠底座。
生产力助手
面向真实生产力场景,Qwen3.7-Max将成为您的深度协作者。依托强大的智能体能力,全面重塑专业工作流:海量信息的全面研读与整合、复杂数据的深度分析与建模、出版级文档与可视化生成——精准承接高复杂度、高强度的企业级任务。
Qwen3.7-Max原生适配主流智能体框架。面向长链路交付任务,支持长达数小时的自主规划与运行,通过上千次工具调用,数十轮版本迭代,持续提升交付物质量。以往需专业团队耗时一至两周的复杂项目,现由Qwen3.7-Max驱动的智能体即可在数小时内完成端到端交付闭环,推动生产力实现真实跃升。
智能体扩展
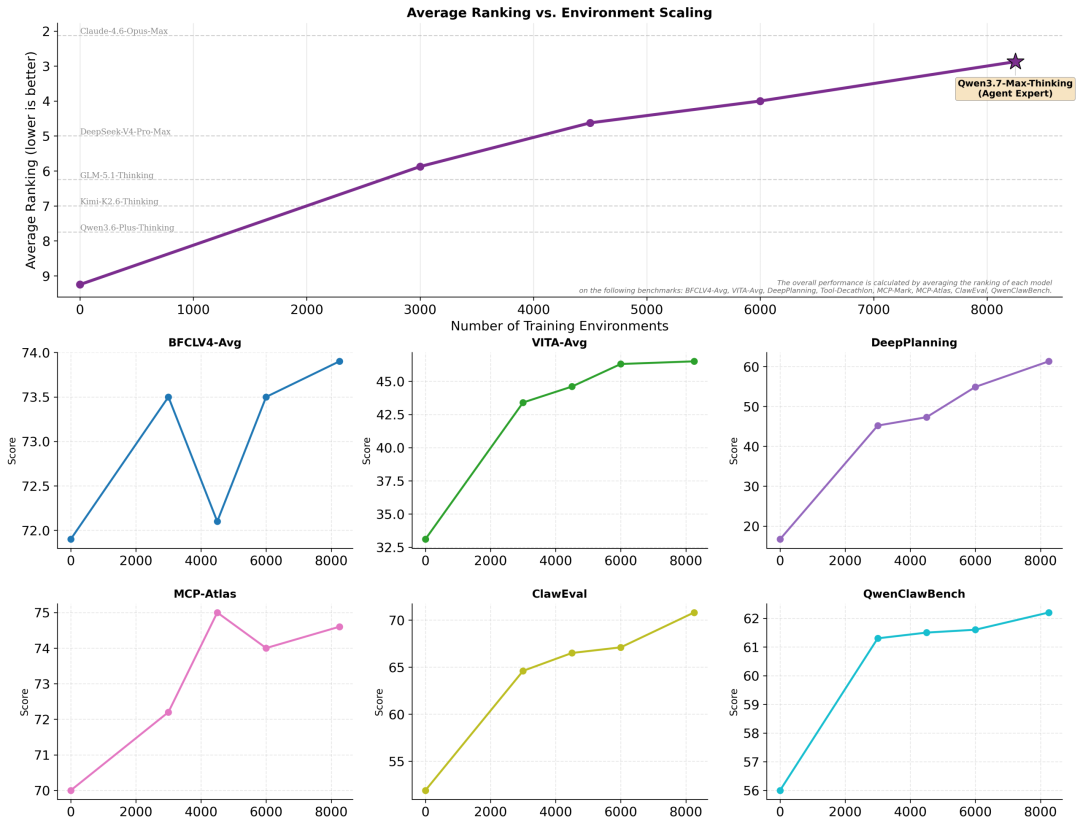
在 Qwen3.5中引入的环境扩展方法基础上,Qwen3.7进一步大幅扩展了智能体训练环境的质量与多样性。正如语言模型从多样化的预训练文本中获得泛化能力,我们发现智能体能力同样可以从多样化的训练环境中实现泛化。
如下图所示,这种环境扩展带来了清晰且稳定的性能提升轨迹,Qwen3.7-Max在综合排名中位列前三,接近Claude-4.6-Opus-Max的水平。值得注意的是,我们评测中所有基准测试所涉及的环境均为训练中从未出现过的全新领域外环境。
我们还观察到扩展行为中一个显著的可预测性:任意基准子集上的性能增益高度一致,可以可靠地预测其余基准或整体平均值的相对增益,表明环境扩展驱动的是真正的能力泛化,而非针对特定基准的提升。关于扩展动态和方法论的进一步分析将在即将发布的技术报告中详细介绍。
跨框架泛化能力
我们的Rollout环境基础设施将每个训练实例解耦为三个正交组件——任务(Task)、运行框架(Harness)与验证器(Verifier),这些组件可自由重组。我们兼容多种运行框架及其迭代版本,并将环境立足于真实场景而非合成替代品。这种解耦设计实现了组合式扩展:同一任务能以极低的边际成本,与不同类型、不同版本的框架及验证器相匹配。更关键的是,它赋能了跨框架与跨验证器的强化学习(RL)训练——使模型在多变的框架配置下处理同源任务,从而迫使其学习具备泛化能力的解题策略,而非依赖特定框架的捷径。在QwenClawBench与CoWorkBench评测中,无论评估时使用何种运行框架,Qwen3.7-Max均展现出强劲且一致的性能,显著超越Qwen3.6系列模型,证实了该模型已真正掌握了解决任务的能力,而非过拟合特定框架。

Qwen3.7-Max可以无缝集成到主流智能体框架和编程助手中,包括Claude Code、OpenClaw、Qwen Code等。