当模型开始同时理解图像、视频乃至物理世界, 并逐步具备行动能力时, 一个问题也随之变得不可回避: 我们是否仍在用 LLM 时代的基础设施, 来训练新一代的多模态大模型?
如果答案是肯定的, 那么问题就不再只是效率上的「还能不能再优化一点」, 而是训练体系本身与模型形态之间已经出现了结构性的错位。全模态训练框架 LoongForge, 正是在这样的背景下提出的一套系统性解决方案。
GitHub 项目地址:https://github.com/baidu-baige/LoongForge
行业背景: 两条主线, 正在重塑 AI 基础设施
过去三年, 大模型领域的变化, 并不只是规模变大, 而是基础假设正在发生改变。单独看, 它们分别属于模型侧与算力侧的自然演进; 但放在一起看, 它们正在重新定义 AI 基础设施应有的形态。
多模态, 正在成为大模型的新底座
从模型架构的演进路径来看, 这一趋势已经相当清晰。早期的多模态模型, 通常是在纯文本 LLM 之外, 通过外挂视觉编码器的方式补充图像理解能力, 例如 InternVL、Qwen3-VL 等。这种方式实现, 本质上仍然是「在语言模型之外增加一个视觉插件」, 两者在训练目标与表征空间上并未真正统一。
而新一代模型已经开始走向另一条路径。以 Ernie 4.5、Qwen3.6、Kimi K2.6 等为代表, 多模态能力被直接纳入预训练全过程, 视觉与语言从一开始就共享同一套学习机制。这种变化意味着, 多模态不再是可以按需添加的能力, 而是构成模型能力上限的基础结构本身。
具身智能的兴起, 使这一判断进一步得到强化。VLA (Vision-Language-Action) 模型并不是对多模态的替代, 而是建立在 VLM 之上的自然延伸: 只有当模型能够稳定地看懂和理解世界, 才谈得上进一步与物理环境交互。从这个角度看, 多模态的重要性不止体现在视觉理解, 而是在于它构成了 AI 向真实世界延伸的起点。
算力从单一供给走向多元异构
与此同时, 算力体系也在发生变化。以昆仑芯 P800 为代表的国产芯片, 已经从早期的单点探索进入到规模化落地阶段, 千卡级集群参与大模型训练逐渐成为常态。算力来源的多元化, 正在成为行业的基本现实。
这带来了一个新的要求: 训练框架需要具备跨平台运行能力。「一套代码, 在不同硬件上稳定运行」, 不再只是工程优化目标, 而是直接关系到模型迭代效率与成本控制的基础能力。
核心挑战: 多模态时代的能力错配
多模态训练带来的变化, 并不是单一维度的复杂度提升, 而是多种异构性的叠加: 数据从文本扩展到图像、视频甚至动作信号, 模型结构从单一主干演变为多组件协同系统。与此同时, 算力平台也从单一 GPU 走向多种硬件共存。
相比之下, 当前主流训练框架的设计前提仍然是「数据同质、结构单一、平台固定」。在这种前提下构建的系统, 在面对多模态任务时, 逐渐显露出不匹配的问题。
挑战 1: 迭代速度被工程复杂度拖累
多模态模型研发的重点已从「单一主干的规模扩展」转向「多组件的联合调优」。
以 Megatron 为代表的高性能框架, 模型定义与分布式策略深度耦合, 每接入一个新模型都需深入底层代码, 调整模型组网, 工程门槛较高, 适配周期(883436)动辄数周; 而以 FSDP 为代表的方案, 虽然模型接入快速、调试方便, 但在大规模训练场景下, 通信效率与显存管理仍有优化空间, 在极致性能要求下存在瓶颈。
结果是, 团队不得不在「快速迭代」与「高效性能」之间反复取舍。
挑战 2: 异构结构带来的隐性性能损耗
多模态训练面临两个突出的效率问题: 一是视觉组件 (ViT) 与语言组件 (LLM) 的参数量差异悬殊, 传统框架「一刀切」的并行策略无法为不同组件分配最优资源; 二是多模态数据的高度不均匀性, 会在大规模集群中放大为明显的负载不平衡, 导致部分 GPU 长时间等待最慢节点。
这些问题不会中断训练, 却持续降低整体效率, 使算力成本在不知不觉中被放大。
挑战 3: 跨平台迁移的沉没成本
社区框架深度绑定特定硬件生态, 企业尝试国产芯片时往往需要维护两套完全独立的代码分支。
更关键的是, 即便完成迁移, 因缺乏框架级深度优化, 不同平台之间的性能表现也难以对齐。「可以运行」与「高效运行」之间, 存在明显差距。
LoongForge 产品定位与核心价值
在上述背景下, 百度(BIDU)百舸开源发布全模态训练框架 LoongForge, 旨在从根本上解决多模态训练中的结构性问题。
LoongForge 与 LoongFlow 均属于百度(BIDU)百舸的 Loong 开源系列。
这套框架由百度(BIDU)百舸 AIAK 训练加速套件演进而来, 以 Megatron 为核心引擎, 并针对全模态场景进行了原生重构。LoongForge 已在 GPU 与昆仑芯 XPU 两大平台、数千卡规模集群上完成长期生产验证, 覆盖 LLM 到 VLM、VLA 等多种业务场景。
LoongForge 为原生多模态时代提供一套统一、高效、易用的训练加速解决方案。
统一: 一套框架覆盖 LLM、VLM、VLA、Diffusion 等不同场景, 内置 20+ 模型族标准组件, 原生兼容 DeepSeek、Qwen、InternVL、LLaVA-OV、ERNIE、MiniMax、MIMO, 以及 Pi0.5、WAN 等主流模型。贯通预训练到 SFT 全流程, 兼容 NVIDIA GPU 与昆仑芯 XPU 多硬件平台。
高效: 覆盖 LLM 基座优化、多模态专项优化, 到底层算子加速的完整链路。LoongForge 在主流模型上普遍实现 15%~45% 的端到端训练加速, 在 DeepSeek V3.2 等前沿架构上实现倍级性能提升, 并在 5000+ 卡昆仑 P800 集群上实现 90%+ 的线性扩展效率。
易用: 依托统一的模型层抽象, 将模型拆解为 Encoder、Foundation、组合调度三层。新模型接入只需注册对应组件, 通过 YAML 配置完成模块拼接与策略配置, 无需修改底层代码, 适配周期(883436)从数周压缩至天级。
LoongForge 架构设计与核心技术能力
LoongForge 的整体架构由模型层、系统层与硬件层构成, 这三层分别对应多模态训练中的工程复杂性、系统效率与算力平台割裂问题。

模型层: 统一抽象, 降低多模态模型构建门槛
多模态模型种类繁多, 但底层结构有一个共同规律: 骨干始终是 LLM, 差异在于外围挂接了哪些模态的编解码器。
LoongForge 在 Megatron 之上构建了统一的模型层组网抽象, 将多模态模型拆解为感知编码层 (Encoder)、生成主干层 (Foundation)、组合调度层 (OmniCombinationModel) 等三个部分。
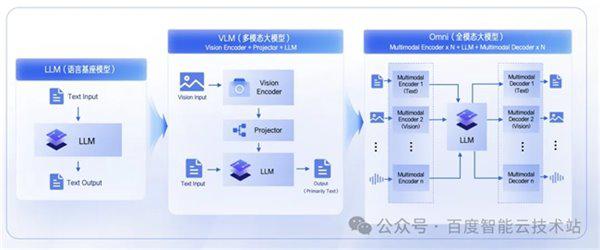
通过一份 YAML 配置文件, 即可自动完成不同组件的组网与并行策略配置, 跨层协作的复杂性全部由框架接管, 对模型开发者完全透明。

系统层: 端到端优化, 释放多模态训练效率
LoongForge 的优化思路是逐层叠加, 先把 LLM 基座的训练效率做到极致, 再针对多模态引入的新瓶颈逐项击破。多模态训练的上限, 首先取决于语言基座的效率地基; 地基不稳, 上层优化再精细也是空中楼阁。

下文选取若干代表性方向加以说明。
针对 LLM 基座的优化:
CCT 算通传并行: 打破 MoE 长序列训练的「显存-通信」二选一困局。MoE 模型做长上下文训练时, 专家并行 (EP) 引入的 All-to-All 通信带来了显著通信开销。为隐藏这一开销, 业界方案通常将计算模块细粒度拆分, 但这一设计与长序列训练必备的全层重计算存在根本冲突。结果是, 要么通信快但显存爆炸, 要么显存省但通信慢, 两者无法共存。LoongForge 提出 CCT (Computation-Communication-Transfer) 通算传并行方案, 引入显存 offload 策略, 并将计算、通信、数据传输进行统一调度与编排, 实现极致的 overlap, 从而打破这一僵局。实测 Qwen3-30B-A3B 32K 序列训练性能在 A800 集群中提升 16%; 社区同类方案在相同条件下因显存不足直接 OOM, 通信优化根本无法启用。
ChunkPipe 流水线并行: 让超长序列训练在中小规模集群上真正可落地。上下文窗口持续拉长,1M 级别超长序列的训练需求正在成为现实。但在 TP、PP、EP 等并行度已占满有限集群资源的情况下, 往往已无余量开启序列并行, 使得训练任务无法运行。LoongForge 实现 ChunkPipe 流水线并行, 将超长序列的显存开销从「随长度线性增长」转为「可控的固定开销」, 不依赖序列并行即可突破显存瓶颈。
DSA 算子融合: 针对 DeepSeek V3.2 的稀疏注意力架构实现端到端加速。LoongForge 对注意力计算全链路进行了深度算子融合与优化, 涵盖索引内核、稀疏注意力、MQA Absorbed KV 布局、序列拼接等多个关键环节。相比非 CUDA 融合版本, 端到端训练性能提升约 5 倍。
针对多模态架构的优化:
DP 负载均衡: 消除多模态数据异构带来的隐性算力损耗。多模态样本由单图、多图、视频、纯文本混合组成, 序列长度差异极大。传统数据并行将样本平均分配到各 GPU, 实则因 Attention 的二次复杂度特性, 各卡实际计算量可能相差悬殊。LoongForge 构建了自动化的计算负载均衡机制, 在每轮迭代前对样本分配进行动态重排, 显著收窄各 Rank 间的负载差距。这是 LoongForge 在昆仑芯千卡级集群训练中实现 90%+ 线性扩展效率的关键支撑之一。
模型异构并行: 让 ViT 与 LLM 各用最优策略, 而非被迫共享一套配置。典型 VLM 模型中,ViT 参数量约 300M,LLM 主干可高达数百 B, 两者相差数百倍。LoongForge 实现组件级异构并行, 允许视觉编码器与语言主干各自独立配置最优策略, 并进一步实现了 Encoder-Decoder 全分离并行训练, 从根本上消除了视觉编码器引入的流水线负载不均与气泡损耗。实测 Qwen3-VL-30B 32K 序列训练, 相比社区方案端到端吞吐提升高达 50%。
混合精度训练优化:
自适应 FP8: 让混合精度训练「从全局统一配置」走向「按场景动态最优」。FP8 虽然能显著提升训练效率, 但在 MoE 小专家、高并行度、短序列, 以及视觉-语言混合的多模态场景下, 额外的量化开销可能导致性能回退。LoongForge 提出自适应 FP8 (Selective FP8) 机制, 基于离线 Benchmark(BHE) 生成动态精度策略, 在模型初始化阶段按层、按组件自动选择 FP8 或 BF16, 并支持 ViT 与 LLM 分别采用独立策略, 避免「一套配置套全模型」的低效。这样既保留了 FP8 的吞吐收益, 又规避了不利场景下的回退; 在 Qwen3-VL 235B 的 16K 训练中, 实测相比全量 FP8 进一步提升约 10%。
硬件层: 一套代码, 多平台运行
GPU 侧通过 PyTorch / CUDA 原生对接 Megatron, 完整保留原生训练的极致性能;XPU 侧通过插件化的 XPU_Plugin 硬件接入层, 封装昆仑芯与 NVIDIA GPU 之间的底层接口差异, 实现 Megatron 引擎的零侵入改造。
同一份训练代码仅需切换硬件环境变量, 即可在 NVIDIA GPU 与昆仑芯 XPU 两大平台上无缝切换运行。

性能数据: 在同等硬件条件下, 数字说话
以下为 LoongForge 在多个典型场景下的实测表现, 所有对比均为各框架相同硬件配置下最优可运行方案。

在同等 GPU 硬件与任务条件下,LoongForge 在主流模型上普遍实现 15%~45% 的端到端训练加速。在 DeepSeek 等前沿架构上实现 4.8 倍性能提升, 同时得益于显存层面的深度优化, 相同硬件条件下可训练的序列长度显著增加。此外, 在 5000+ 卡昆仑 P800 集群上,LoongForge 达到 90%+ 的线性扩展效率。
典型案例: 经过真实生产打磨的框架
LoongForge 的能力不来自 Benchmark(BHE), 而是在真实生产环境中持续打磨出来的结果。
案例 1:LLaVA-OneVision-2.0
LLaVA-OneVision-2.0 是一款全开源的全帧率多模态视觉语言模型。面向真实业务场景中的视频理解需求, 该模型在不丢帧的前提下, 重构了视频理解路径, 优化了帧级信息提取与视觉编码方式, 显著减少了冗余计算, 从而将视频 token 消耗大幅降低。在显著降低成本与延迟的同时, 其视频理解能力可达到与 Qwen3-VL 相当的水平。
在训练与优化过程中,LoongForge 提供了多模态训练框架层面的系统性支持。基于其在异构并行、负载均衡等方面的能力, 模型训练的资源利用率和迭代效率获得了显著改善, 为整体研发过程提供了稳定支撑。
案例 2:LLaVA-OneVision-1.5
引入全新 RICE-ViT 视觉编码器的开源多模态模型。团队数天内完成新编码器适配, 在 128 张 A800 上完成 8B VLM Stage-1.5 预训练。
框架适配与性能优化全程开箱即用, 验证了 LoongForge 快速支持新架构的工程能力。
案例 3: 千帆 VL 系列
Qianfan-VL 模型系列是面向企业级应用场景强化打造的多模态大模型系列, 在保持通用多模态能力的基础上, 针对产业落地中的高频场景进行了深度优化。
该系列涵盖 3B、8B、70B 三个规格的企业级多模态大模型, 全部基于昆仑芯 P800 芯片, 在 5,000+ 卡的超大规模分布式训练系统上完成训练。训练过程采用 3D 并行策略与通信-计算融合技术, 实现了 90% 以上的集群扩展效率, 并高效完成了 3T tokens 多模态数据的处理。
三个规格的模型共用一套框架代码, 核心能力在生产环境中得到全面验证, 充分证明了 LoongForge 在国产算力大规模集群下的稳定性与性能表现。
操作演示:YAML 配置驱动, 开箱即用
LoongForge 将模型定义、训练策略、数据处理到权重管理的全流程, 统一收敛到配置驱动的操作范式: 一份 YAML 定义模型组网, 一行参数切换并行策略, 一条命令启动训练。如下展示从组网到训练的完整流程。
1. 模型组网: 换基座, 只需改一行配置
LoongForge 通过声明式配置, 支持将不同模态组件灵活组合为完整的多模态模型。以 Qwen3.5-35B-A3B 为例, 一份 YAML 即可完成视觉编码器、投影层与语言主干的组网:

如果需要将语言主干替换为 DeepSeek V3, 仅需修改如下引用路径:

2. 训练配置:Megatron 用户零学习成本
LoongForge 保留 Megatron 原生参数风格, 同时支持通过 Hydra 对不同组件独立配置并行策略与冻结策略。
基础训练参数 (与 Megatron 兼容):

组件级独立配置 (Hydra 扩展能力), 例如:

3. 加载权重: 从离线转换到在线加载
LoongForge 既支持将 HuggingFace 权重离线转换为 Megatron 训练格式, 也支持直接加载 HuggingFace 格式权重启动训练, 跳过转换步骤。训练完成后可一键导出回 HF 格式, 实现与下游社区生态的无缝衔接。

4. 处理数据: 一条命令, 数据就绪
LoongForge 内置数据预处理工具链, 可将原始数据一键转换为框架兼容的数据格式。示例命令如下:

5. 启动训练:20+ 模型族, 开箱即跑
LoongForge 对主流开源模型提供了完整支持。用户可在 GitHub 项目的 configs / models / 目录获取模型组网配置示例, 在 examples / 目录获取数据预处理脚本与训练启动脚本。
完整的模型支持列表, 详见:
https://loongforge.readthedocs.io/en/latest/get_started/support_model.html
路线图: 持续迭代方向
基于当前生产级实践,LoongForge 将聚焦以下方向持续迭代:
模型生态: 持续扩充模型适配矩阵, 覆盖 Kimi K2.6、DeepSeek V4 等新开源(300109)基座, 并增强对具身领域模型的深度支持。
长序列训练: 完善百万级超长序列的训练支持, 扩展策略兼容性, 降低长上下文场景下的显存与资源门槛。
训练性能: 从并行策略、算子融合、显存优化、通信调度等维度持续提升引擎效率, 进一步释放大规模集群算力。
训推一体: 打通训练与推理的协同优化链路, 提供 MTP 扩展最佳实践, 提升推理阶段的解码效率与端到端交付速度。
易用与工具链: 持续降低模型接入与调优门槛, 完善框架周边工具链, 让开发者将更多精力回归模型创新本身。
工具决定速度, 基础设施决定行业高度
科技史上有一个反复出现的规律: 当一个领域的复杂性超出个人或小团队的驾驭边界, 总会出现一个工具, 把复杂性收进去, 把创新的门槛降下来, 然后这个领域的发展速度就会突然加快。
CUDA 让研究者无需掌握图形学知识就能利用 GPU 做通用计算, 深度学习的规模化由此真正启动。PyTorch 把分布式训练、自动求导封装成可直接调用的工具, 模型创新的速度因此大幅提升。
今天, 多模态大模型训练正处于这样一个临界点。
OpenAI 核心基础设施构建者翁家翌在公开分享中多次强调:「当前大模型的竞争, 拼的不是谁的 Idea 更精妙, 而是 AI Infra 的正确性与单位时间内的迭代次数。」
他同时指出:「Idea 是廉价的, 能被快速验证的 Idea 才值钱。」
真正拉开差距的, 是同样算力下, 谁能跑更多实验、谁能更快试错、谁能更稳定地训练出高质量模型。AI 工程与基础设施, 正在成为大模型时代最核心的能力边界。
模型架构快速演进、数据形态高度异构、算力平台多元分化, 这些复杂性已成为行业普遍的摩擦与损耗。LoongForge 所要做的, 正是把这层复杂性收进框架, 让开发团队把更多精力重新投入到模型创新本身。
当训练不再成为瓶颈, 多模态时代的加速, 才会真正开始。
LoongForge 采用 Apache 2.0 协议开源, 让统一、高效、易用的训练能力, 逐步沉淀为行业的公共基础设施, 让更多有价值的 Idea 能被快速验证。